

官网×AI深度协同:构建新流量生态的智能获客引擎

在 AI 时代,大家更希望官网能够自主去承接流量、过滤出有价值的线索,而不是反过来向团队索要工作量。如果网站做好了,依然需要员工每天用大量的时间耗在修改内容、记录后台线索上,那它不仅没能成为高效的获客武器,反而变成了一个持续消耗人力的成本包袱。
要解决这个问题,营销枢纽通过官网 + AI 的组合,构建起一个自动化的获客系统。这套系统将 AI 能力直接渗透到网站的内容生成、日常运营和线索获客中,让网站具备理解企业自身业务的能力。过去那些必须依靠人工手动修改、紧盯的业务,由此转化为系统底层自行运转的流程。
这套系统不仅在于精简了日常工作,更重要的是能帮企业在全新的流量规则下抢占先机。当如今的大模型和各大搜索引擎在全网筛选并引用信息时,一个能够自主优化、实时响应的网站,远比纯靠人工堆砌的页面更能快速卡位。只有这样,官网才能在新的技术环境下,真正变成帮企业持续抓取商机的利器。
一、运营模式对比:传统建站 vs 官网+AI的自动化获客系统
为了理解营销枢纽这套官网+AI的自动化获客系统的价值,可以与传统的建站模式进行对比。它们的区别不仅是加入了 AI 工具,还在于可以让企业官网的数字资产可以自己运转起来。
对比维度 | ||
|---|---|---|
| 依赖专业开发与文案团队,响应周期长。需要人工写稿件、写案例,内容产出受限于个体的精力和专业上限。 | ||
| 需要在后台耗费大量时间,给成百上千个页面逐一手动去配 TDK,机械且繁琐。 | ||
| 网站协议陈旧,缺乏结构化数据,AI 大模型在全网检索时无法识别,沦为信息孤岛。 | ||
| 依靠留资表单或传统触发式客服。遇到深夜、周末或人工离线时,无法及时响应,线索流失率极高。 | ||
| 销售拿到只是一个冰冷的电话号码或名字,跟进前需要花费大量时间去人肉搜索对方的背景,效率低下。 |
1.内容生产:解决网站内容更新难、产出慢的问题
要让官网发挥作用,首先要解决网站内容从无到有的生产效率,让业务信息能够快速且专业地呈现。
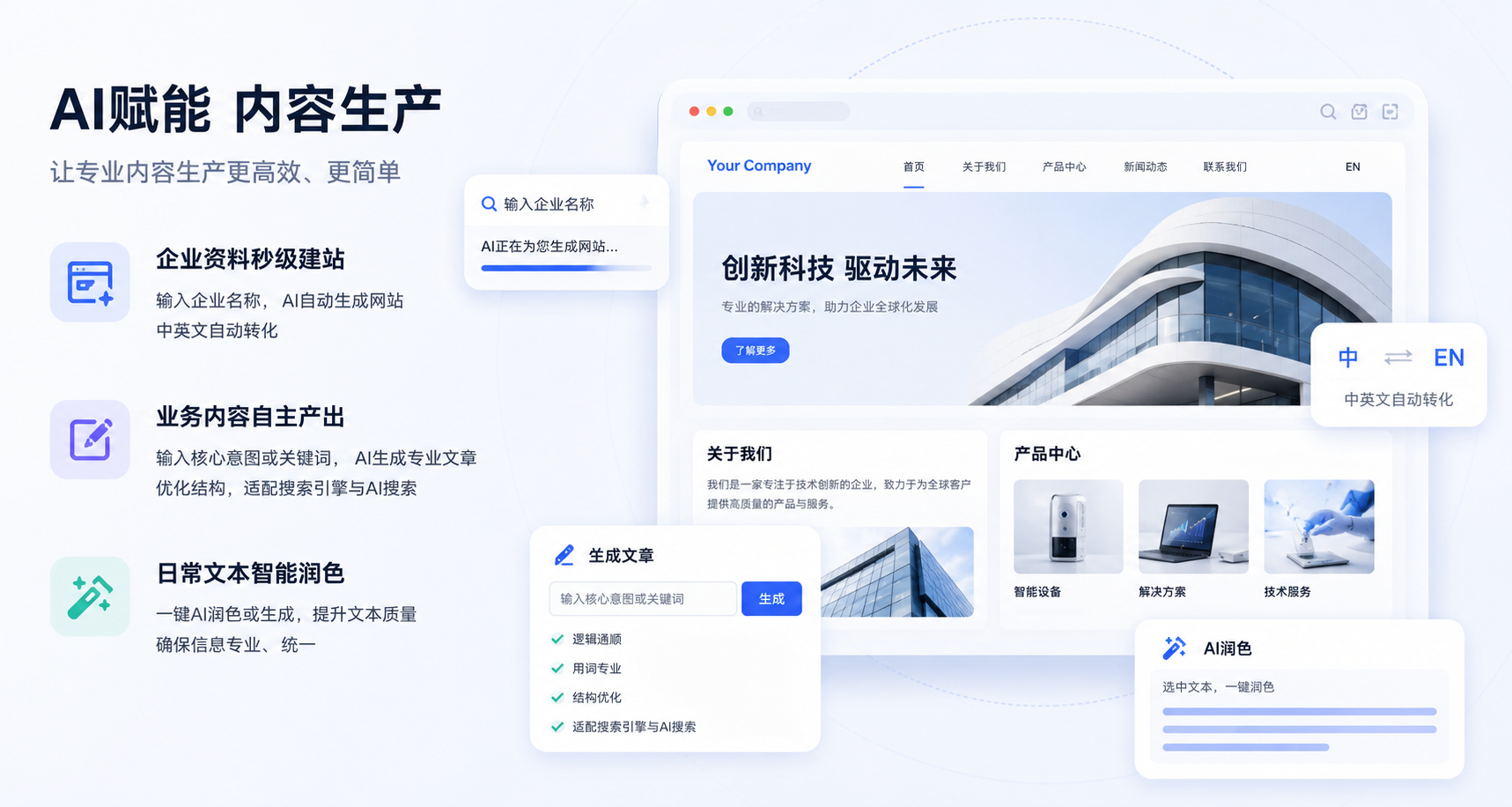 (AI生成图:AI赋能内容生产)
企业资料秒级建站:搭建新网站或拓展海外新站点时,用户只需在后台输入企业名称,系统就会自动在网络上检索该公司的公开简介与核心业务,自动匹配合适的设计风格,一键生成包含首页、关于我们、产品中心的完整网站,并支持中英文自动转化。
(AI生成图:AI赋能内容生产)
企业资料秒级建站:搭建新网站或拓展海外新站点时,用户只需在后台输入企业名称,系统就会自动在网络上检索该公司的公开简介与核心业务,自动匹配合适的设计风格,一键生成包含首页、关于我们、产品中心的完整网站,并支持中英文自动转化。
业务内容自主产出:网站上线后的内容更新不再依赖人工写稿。系统可以深度学习企业已有的文章风格和产品资料,只需说明核心意图或提供几个关键词,就能源源不断地输出逻辑通顺、用词专业的文章,并且在生成内容时会深度优化文本结构,使其更加契合传统搜索引擎和新型 AI 搜索的抓取偏好。
日常文本智能润色:这种能力覆盖了网站的各个文字角落。无论是产品功能介绍、活动公告还是客户案例,员工在编辑时只需选中文字并点击“AI 润色”或“AI 生成”,系统就能快速完成润色的扩写,确保所有对外发布的信息在专业度上保持高度统一。
2.日常运营:无需人工干预的后台AI自动优化
内容发布后,如何让它们被搜索引擎和 AI 搜索精准抓取,以往需要耗费大量时间。现在,这些工作全部沉淀到了底层。
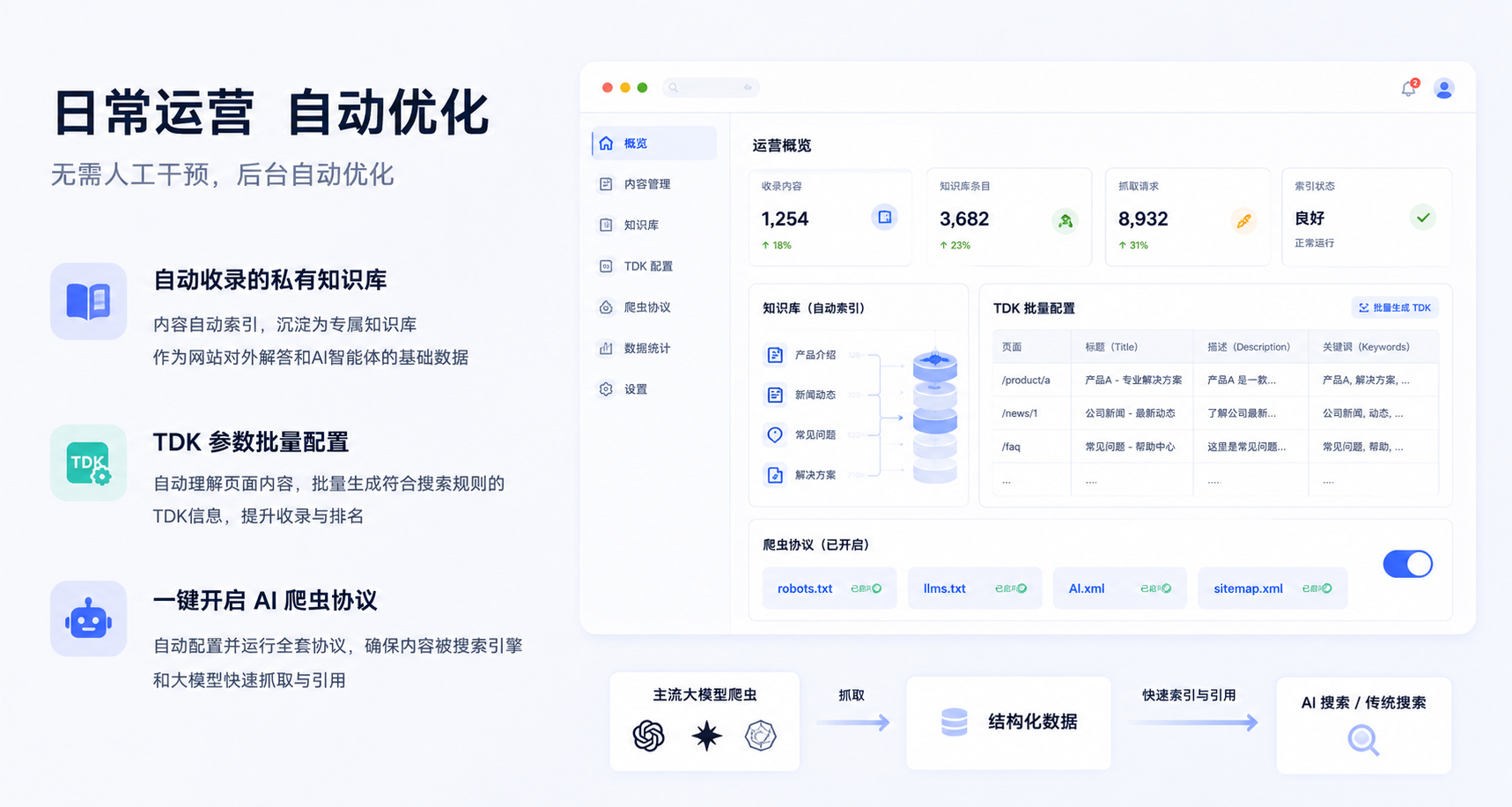 (AI生成图:日常运营AI自动优化)
自动收录的私有知识库:站点里发布的每一篇文章、每一个产品、每一条常见问题,都会被系统自动索引并存入一个专属的知识库中,在后台默默运行,作为网站对外解答和 AI 站点智能体读取的基础数据。
(AI生成图:日常运营AI自动优化)
自动收录的私有知识库:站点里发布的每一篇文章、每一个产品、每一条常见问题,都会被系统自动索引并存入一个专属的知识库中,在后台默默运行,作为网站对外解答和 AI 站点智能体读取的基础数据。
TDK 参数批量配置:面对大量的页面,人工去逐个设置用于优化搜索的 TDK(标题、描述、关键词)非常浪费时间。系统可以直接读取每个页面的实际内容,自动理解其核心意图,并在后台批量生成符合搜索规则的 TDK 信息。这种批量生成的配置,使得站点元数据更加契合传统搜索引擎和新型 AI 搜索的抓取偏好,实现更高效的自主维护。
一键开启 AI 爬虫协议:运营人员只需在后台一键开启,系统就会自动在底层配置并运行 robots.txt、llms.txt、AI.xml 以及 sitemap.xml 等全套协议。当主流大模型爬虫来官网检索时,能直接提供符合其抓取逻辑的结构化数据,确保站内信息能以最快速度被大模型索引和引用。
3.线索获客:24小时客户接待与智能调研
当后台的自动化内容与协议跑通、吸引来进站流量后,系统的最终目的就是锁住线索,并帮销售团队完成转化。
 (AI生成图:智能接待与精准转化)
AI智能体24小时在线接待:基于后台自动生成的私有知识库,官网和团队成员的数字化电子名片可以一键开启 AI 智能体客服。它能像企业资深员工一样理解访客的复杂提问,并给出精准、不套路的业务解答,不漏掉深夜或周末的意向客户。
(AI生成图:智能接待与精准转化)
AI智能体24小时在线接待:基于后台自动生成的私有知识库,官网和团队成员的数字化电子名片可以一键开启 AI 智能体客服。它能像企业资深员工一样理解访客的复杂提问,并给出精准、不套路的业务解答,不漏掉深夜或周末的意向客户。
客户背景智能调研:获客的自动化不只是停留在“拿到一个电话号码”的表面。当表单收集到客户信息后,销售在后台准备联系前,只需输入对方的公司名称,系统就会立刻联网检索其工商资料、业务范围以及近期动态,自动生成一份详细的客户画像报告。在销售拨通电话之前,对方的大概情况和业务规模已经清清楚楚,极大地提升了成交概率。
三、核心业务疑问直击
Q1:文章提到的 robots.txt、llms.txt 等一键开启的 AI 协议,跟传统的网站 SEO 有什么区别?
A:传统的 SEO 是为了迎合百度、谷歌等“网页搜索引擎”,让它们按关键词排位置;而 llms.txt 和 AI.xml 等新协议,是专门给 DeepSeek、ChatGPT 等 AI 大模型看的“内容授权书”。一键开启它们,等于明确告诉 AI 爬虫哪些是核心企业资产、可以优先调用并作为回答的引用源,在新型 AI 搜索时代帮企业卡位。
Q2:系统在后台自动联网反查客户公司背景,这合规吗?会涉及隐私问题吗?
A:完全合规。系统调研的信息全部来自互联网公开的工商登记资料、经营范围、企业官网动态以及公开的新闻资讯。系统只是通过算法把这些散落在全网的公开商务数据做了解释和聚合,省去了销售自己去人肉搜索的时间,不涉及任何私密隐私或违规数据。
Q3:AI 自动产出的产品介绍和业务文章,会不会被搜索引擎判定为垃圾内容而降低搜索权重?
A:不会。搜索引擎惩罚的是批量、毫无逻辑、纯粹堆砌关键词的垃圾 AI 内容。而系统产出的内容是基于企业私有资料和真实业务简介进行二次理解与润色的,文本结构规整、逻辑通顺,属于高质量的原创业务解答,反而会受到传统搜索引擎和新型 AI 搜索的抓取偏好。
四、结语:“官网+AI”,让网站自主转化线索
官网建设的终极目的,从来都不是为了单纯的展示,而是帮助企业成功地实现获客与转化。通过“官网+AI”的深度融合,把内容生产、日常运营、客户接待以及线索转化等关键链路,全部加以 AI 辅助并实现自动化的运转。官网才能在全新的流量环境下,真正变成帮企业持续抓取商机的进攻性武器。































请先 登录后发表评论 ~